Introduction to Calculating CV
Calculating the Coefficient of Variation (CV) is a crucial step in understanding the dispersion of a dataset. The CV is a statistical measure that represents the ratio of the standard deviation to the mean, often expressed as a percentage. It’s used to compare the variability of different datasets, even if they have different units or scales. In this blog post, we’ll delve into five ways to calculate CV, exploring both manual calculations and the use of statistical software.Understanding the Formula
Before diving into the methods, it’s essential to understand the basic formula for calculating CV: [ CV = \frac{\sigma}{\mu} \times 100 ] where: - ( \sigma ) is the standard deviation of the dataset, - ( \mu ) is the mean of the dataset.Method 1: Manual Calculation
To manually calculate CV, follow these steps: 1. Calculate the mean of your dataset by summing all the values and dividing by the number of values. 2. Calculate the variance by taking the average of the squared differences from the mean. 3. Find the standard deviation by taking the square root of the variance. 4. Apply the CV formula using the standard deviation and mean calculated.📝 Note: Manual calculation can be time-consuming and prone to errors, especially with large datasets.
Method 2: Using Microsoft Excel
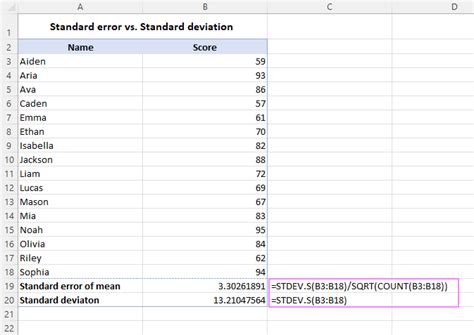
Excel provides an efficient way to calculate CV: - Use theAVERAGE function to find the mean.
- Use the STDEV.S function to find the standard deviation.
- Then, apply the CV formula directly in a cell.
Method 3: Using Python
Python, with its libraries like NumPy, offers a straightforward method:import numpy as np
# Sample dataset
data = np.array([1, 2, 3, 4, 5])
# Calculate mean and standard deviation
mean = np.mean(data)
std_dev = np.std(data)
# Calculate CV
cv = (std_dev / mean) * 100
print(cv)
Method 4: Using R
In R, you can calculate CV using the following code:# Sample dataset
data <- c(1, 2, 3, 4, 5)
# Calculate mean and standard deviation
mean_data <- mean(data)
std_dev_data <- sd(data)
# Calculate CV
cv <- (std_dev_data / mean_data) * 100
print(cv)
Method 5: Using Online CV Calculators
For quick calculations, especially for small datasets or when you don’t have access to statistical software, online CV calculators can be very handy. These tools usually require you to input your dataset, and they calculate the CV instantly.| Method | Description |
|---|---|
| Manual | Time-consuming, prone to errors, but useful for understanding the concept. |
| Microsoft Excel | Efficient for those familiar with Excel, using built-in functions. |
| Python | Flexible and powerful, ideal for large datasets and automation. |
| R | Preferred by statisticians, great for data analysis and visualization. |
| Online Calculators | Convenient for quick calculations, especially for small datasets. |
In conclusion, calculating the Coefficient of Variation can be approached in various ways, each with its advantages and suited to different contexts. Whether you prefer the manual approach for a deeper understanding, the efficiency of software like Excel, the programming versatility of Python or R, or the convenience of online tools, there’s a method that fits your needs. The key is choosing the method that best aligns with your dataset size, the tools you have at your disposal, and your level of comfort with statistical calculations.
What is the Coefficient of Variation used for?
+The Coefficient of Variation (CV) is used to measure the relative variability of a dataset. It’s particularly useful for comparing the dispersion of different datasets that have different units or scales.
How do I choose the best method for calculating CV?
+The choice of method depends on the size of your dataset, your familiarity with statistical software, and the need for precision. For small datasets and quick checks, manual calculation or online tools might suffice. For larger datasets or more complex analyses, using software like Excel, Python, or R is recommended.
Can CV be used for datasets with negative values?
+Yes, CV can be calculated for datasets containing negative values. However, the interpretation might be less straightforward, especially if the mean is close to zero, as the CV could become very large or even undefined if the mean is exactly zero.